Research
“Little strokes fell great oaks.”
- Benjamin Franklin
Initially, most of my research at Penn focused on analyzing electroencephalographic (EEG) recordings - measurements of the changing electrical potential in people’s brains caused by neurons firing. A topic of particular interest for my previous lab is how we can use machine learning to actively predict a person’s behavior (like whether or not they will remember a studied item) based on on their brain activity. We’re still a ways off from mind-reading, but it’s cool stuff.
Nowadays, I’ve shifted from machine learning applications in neuroscience to machine learning theory and methodology. I’m interested in why deep learning models work so well, along with their pitfalls. I hope that gaining a deeper foundational understanding of deep learning will help us develop models that are more performant and more interpretable (or, at least, safer and more predictable).
Theory of deep learning
Inductive bias / implicit regularization
One possible explanation for why neural networks generalize well is that they have some kind of inductive bias that encourages them to learn generalizing solutions (perhaps e.g. a simplicity bias that prevents overfitting). Lots of theory has been devoted to studying how our training methods (e.g. stochastic gradient descent) implicitly regularize models’ effective loss landscape such a way.
The animation below illustrates how the loss landscape of a simple two-parameter model changes as you increase the strength of \(\ell_2\) regularization. The loss landscape is a surface in 3D space, where the x-axis is the first parameter, the y-axis is the second parameter, and the z-axis is the loss. The red mesh is the loss landscape, and the blue contours show the strength of the regularization. As you increase the strength of the regularization, the aggregate loss landscape (in gray) shifts from the original minimum to a new minimum that is closer to the minimizer of the regularization term.
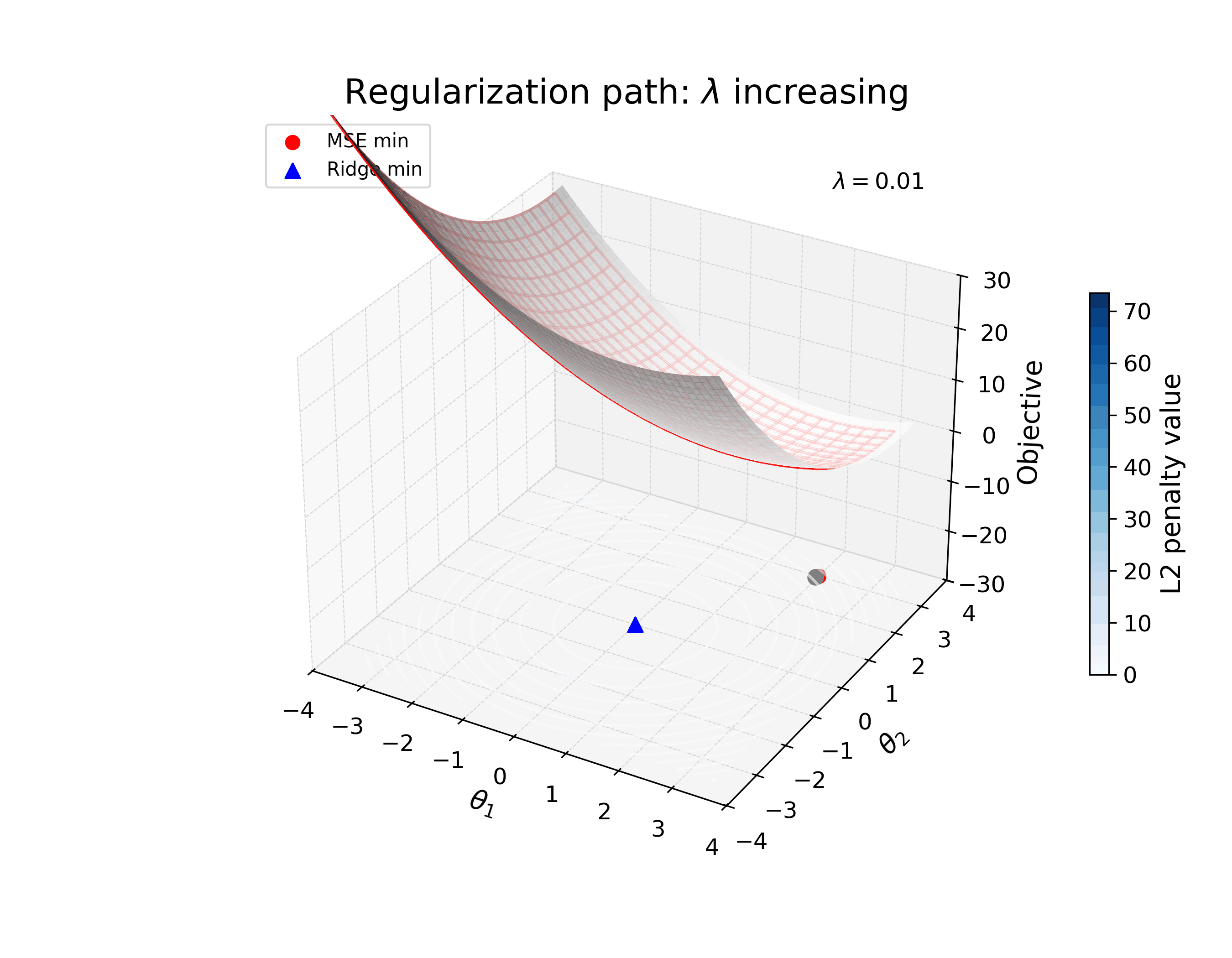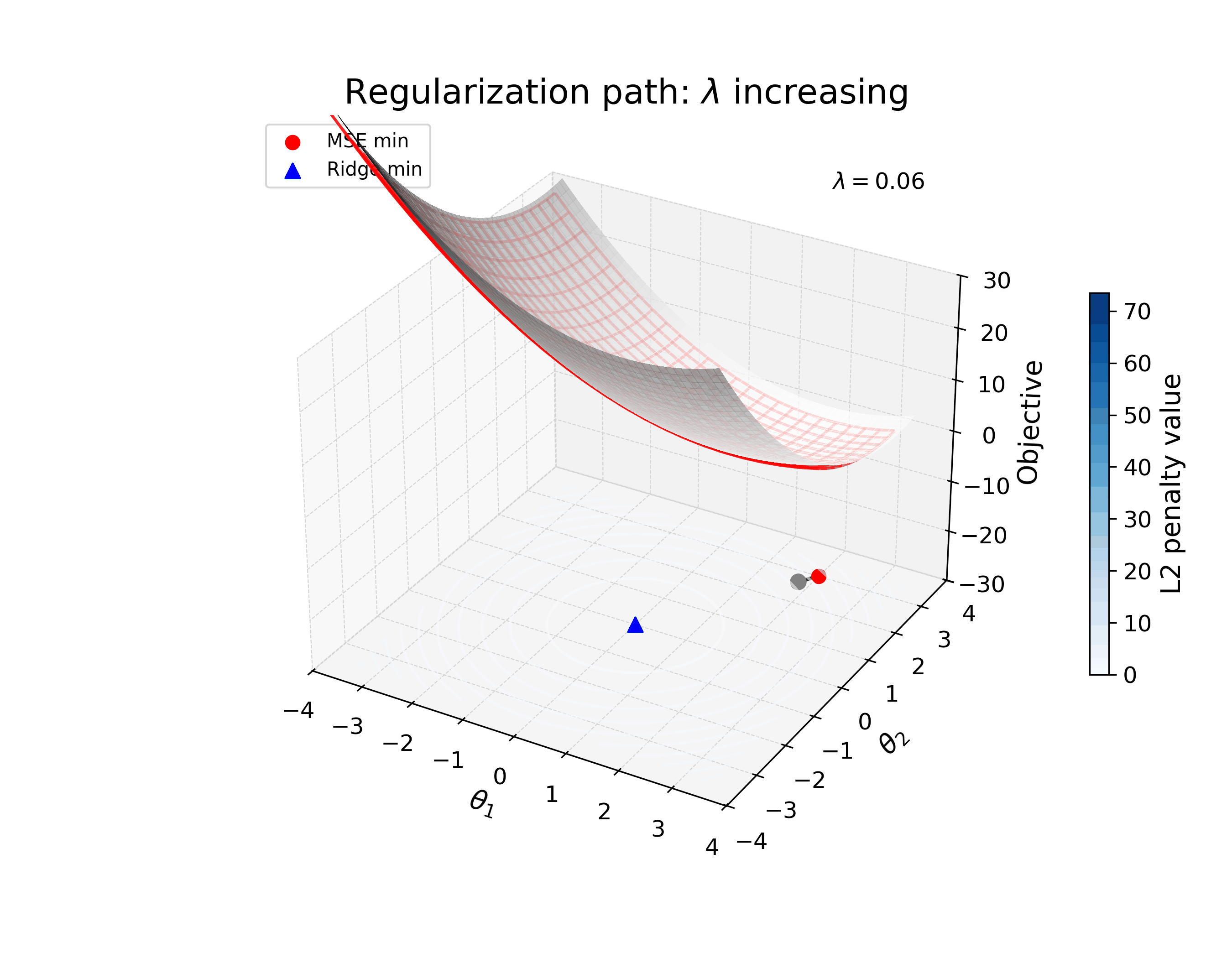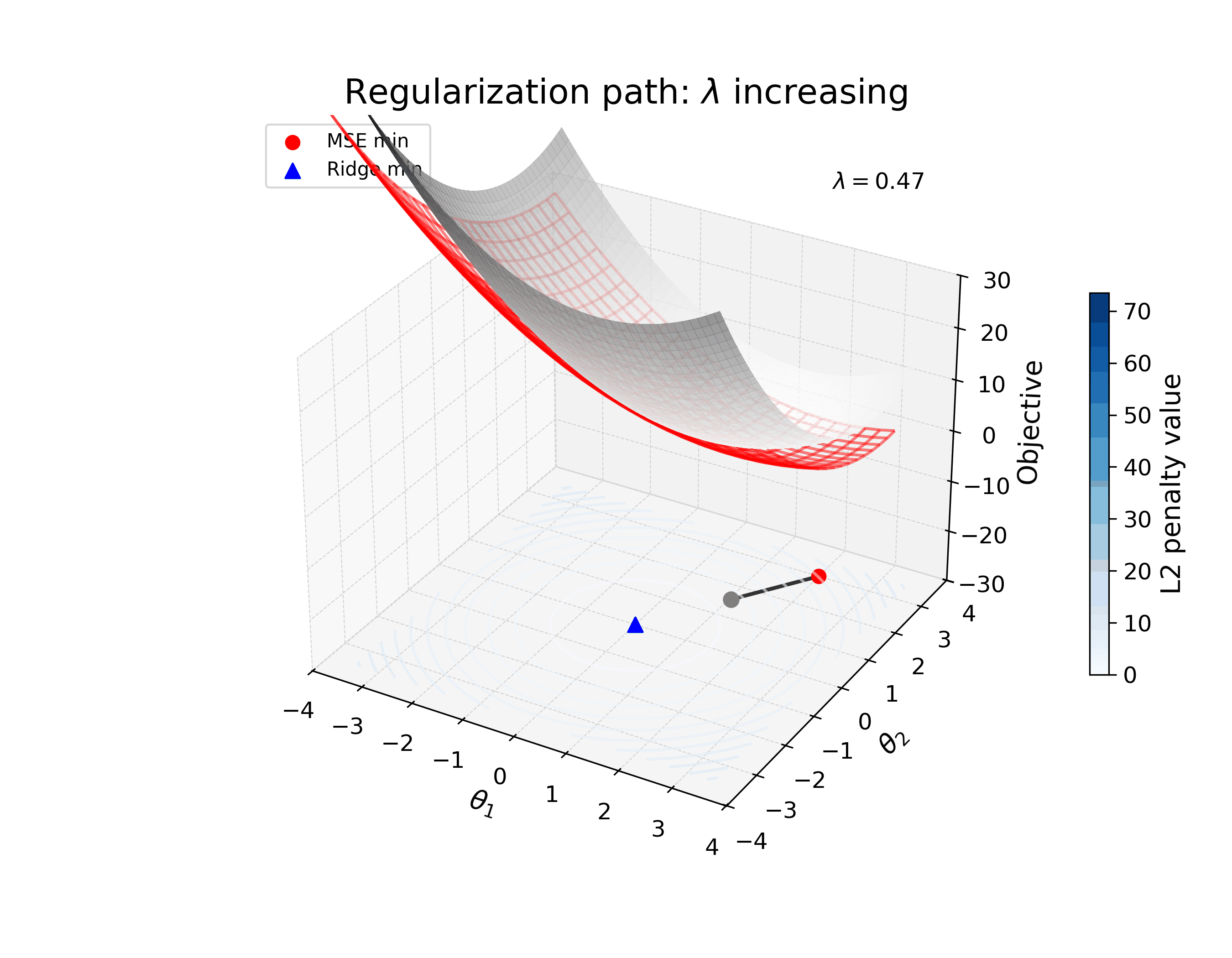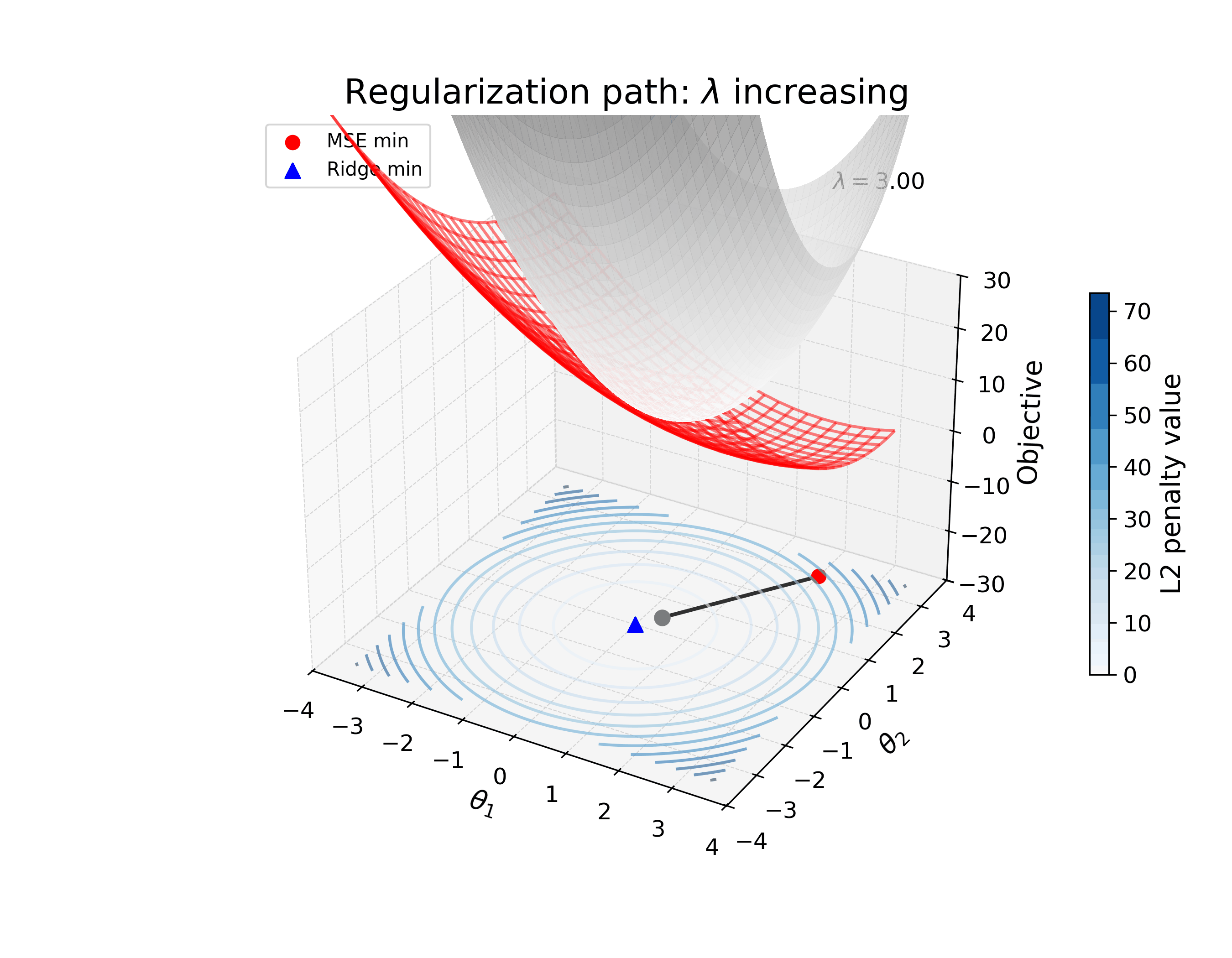
The important thing to realize here is that the new optimum (solution) is not the same as the original – it’s shifted to a new point in parameter space that reflects the regularization applied. I’m interested in how we can study learned solutions like this, and how they differ from the optima of the nominal (unregularized) loss, to reverse engineer the inductive bias of the model.
EEG analysis and machine learning applications
Working towards foundation models for neural data
My master’s thesis was about training deep neural nets to predict behavior (in particular, memory) from neural data aggregated across different people. This is an instance of a type of transfer learning called domain adaptation – essentially you want the model to learn some shared properties of neural activity across brains so that it can predict neural activity in a brain that it’s never seen before. This is similar in spirit to how large language models are trained on large corpora of text so they can learn properties of natural language that generalize to new language-related tasks.
While my work was recognized by an award from my department, we didn’t really have any publishable results. Since then, similar work has come out showing that this kind of approach is successful for many tasks with stronger neural correlates than memory (e.g. motor tasks, sleep stages, stress/emotion, etc.). I’m not actively working on this but think it’s a super cool and promising research direction.
Decoding brain states and improving memory
Paper: Decoding EEG for optimizing naturalistic memory, Journal of Neuroscience Methods
- In this project we asked whether using machine learning to optimize the timing of item presentations during learning could improve memory performance. Presented as a poster at the Cognitive Neuroscience Society (CNS) annual meeting, Context and Episodic Memory Symposium, and MathPsych in spring/summer 2022.
Oscillatory biomarkers of memory
Paper: Hippocampal theta and episodic memory, Journal of Neuroscience
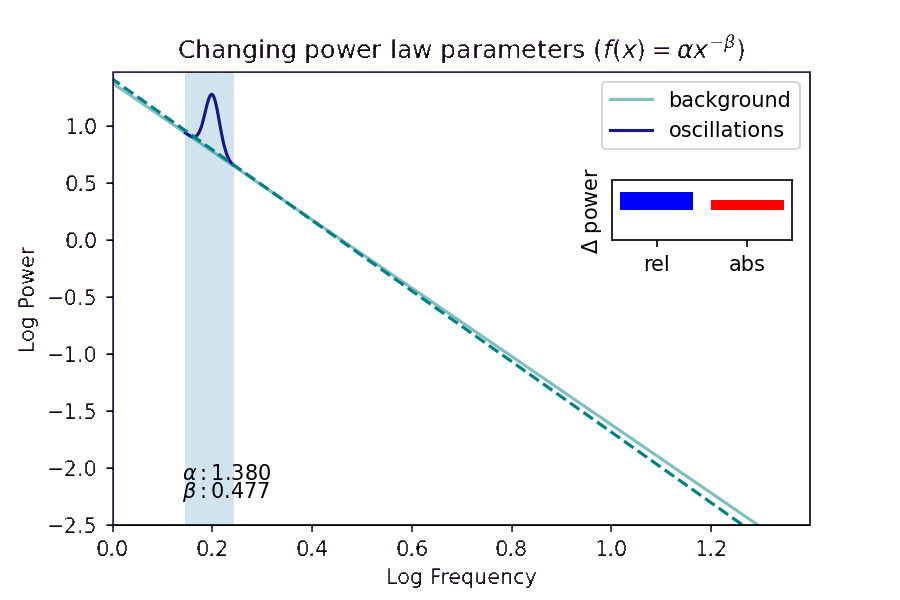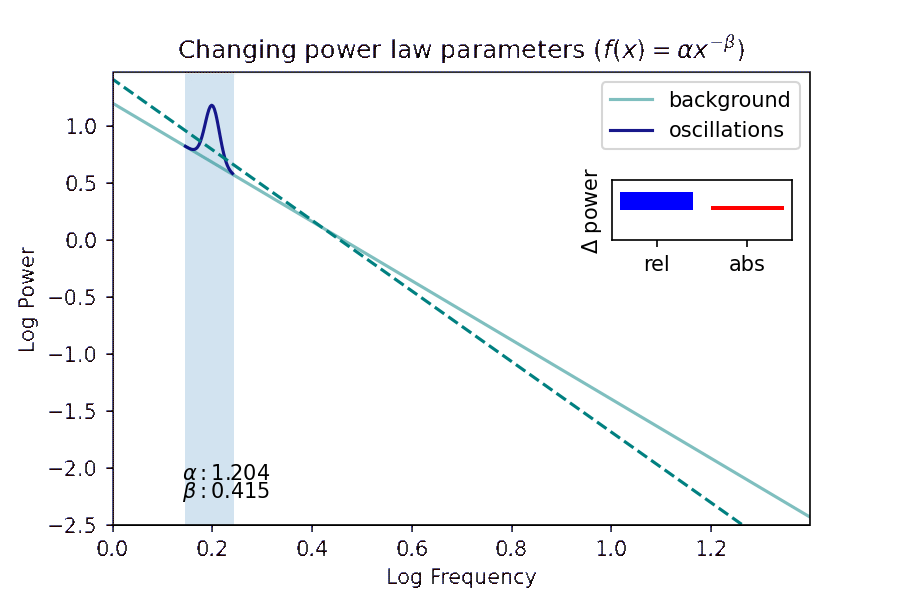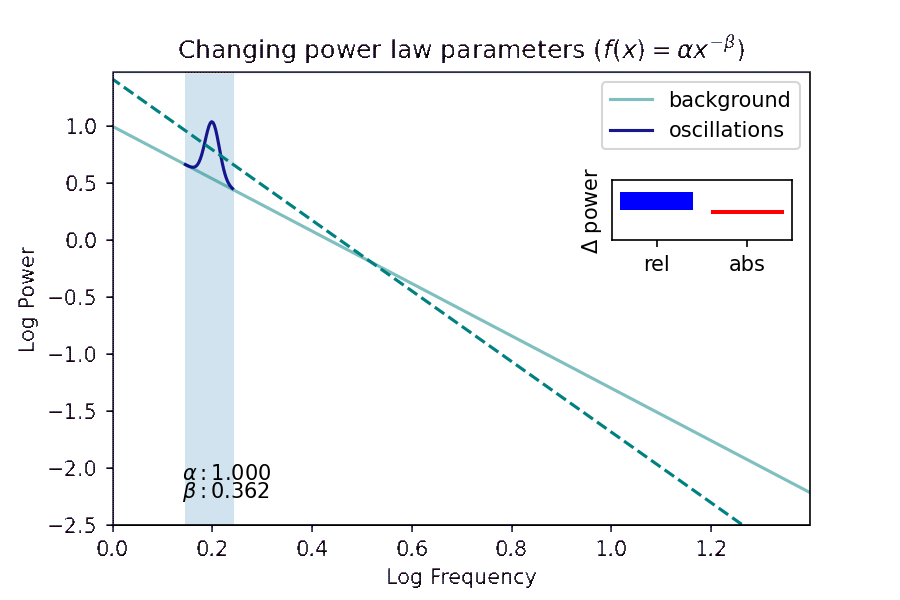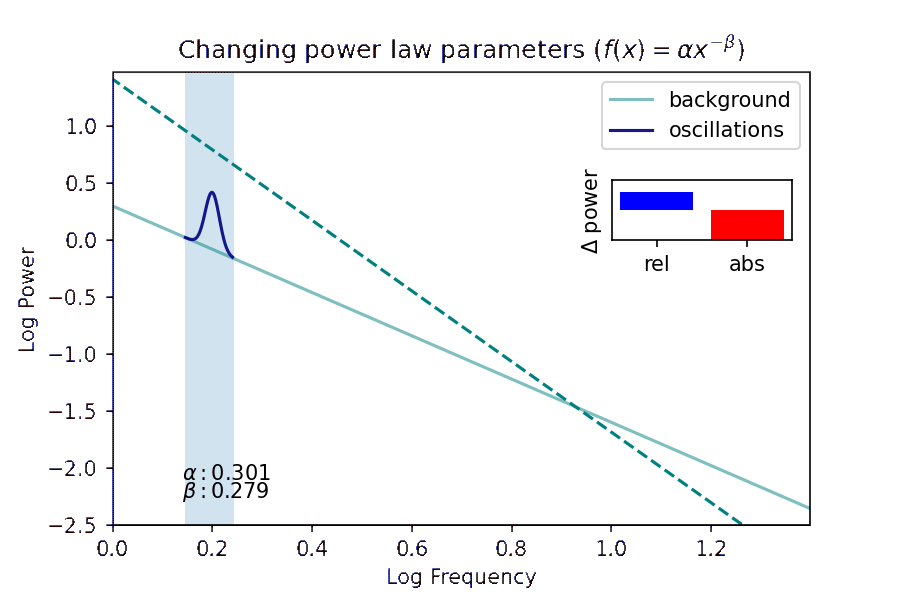
- I investigate how a method of distinguishing pink noise in brain recordings from true brain rhythms helps us understand what patterns of brain activity actually relate to successful memory encoding and retrieval. Presented at the Context and Episodic Memory Symposium in August 2021 and Computational and Systems Neuroscience (COSYNE) in March 2022.
EEG pre-processing methods
Undergraduate Research Project: Optimal EEG Referencing Schemes for Brain State Classification
- Analyzing changing electrical potential requires choosing a reference point for the measurement. When we have some set of electrodes recording brain activity in distinct spatial locations in the brain, should they all be referenced the same way? To a common electrode? To their nearest neighboring electrode? To a weighted sum of other electrodes? I discuss a number of approaches, explain how they act as variable “spatial filters”, and compare their utility for classifying brain state and memory success.
Sports Analytics
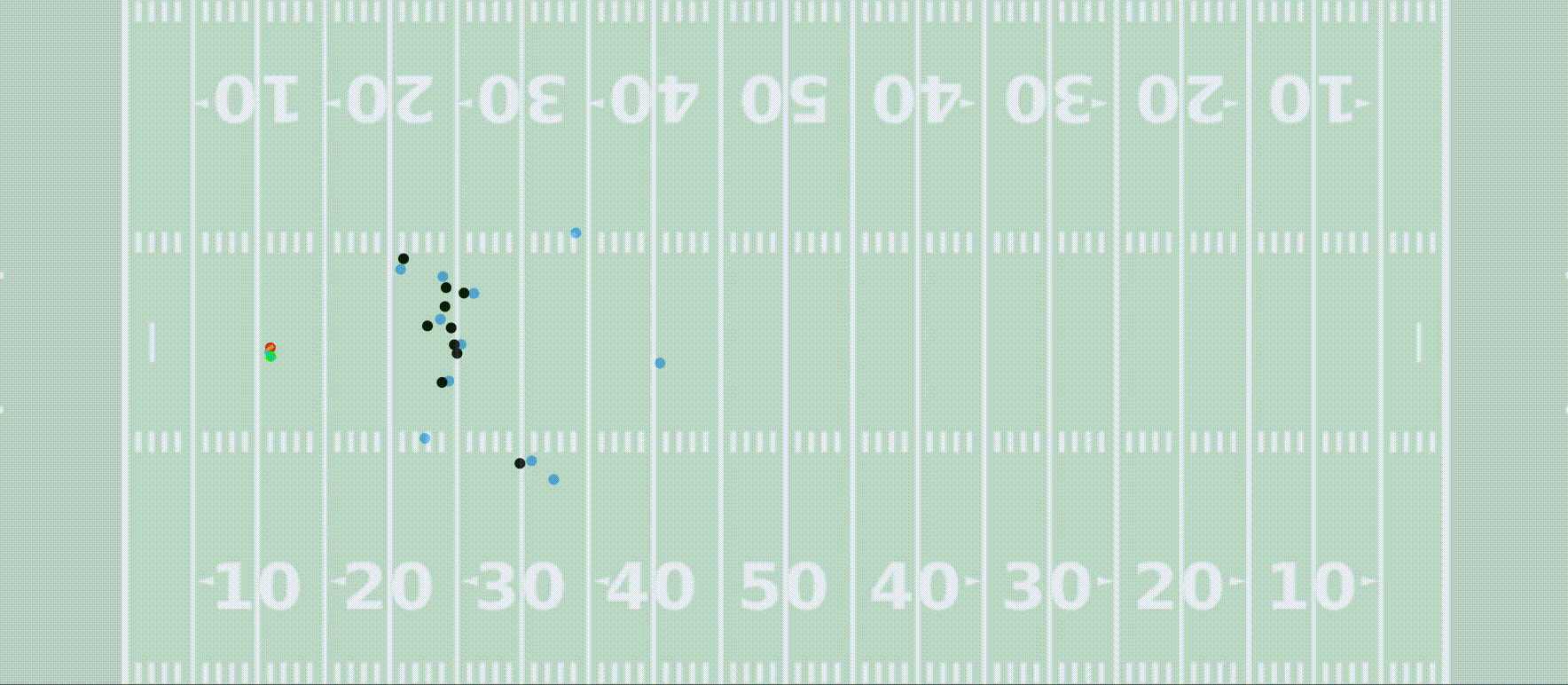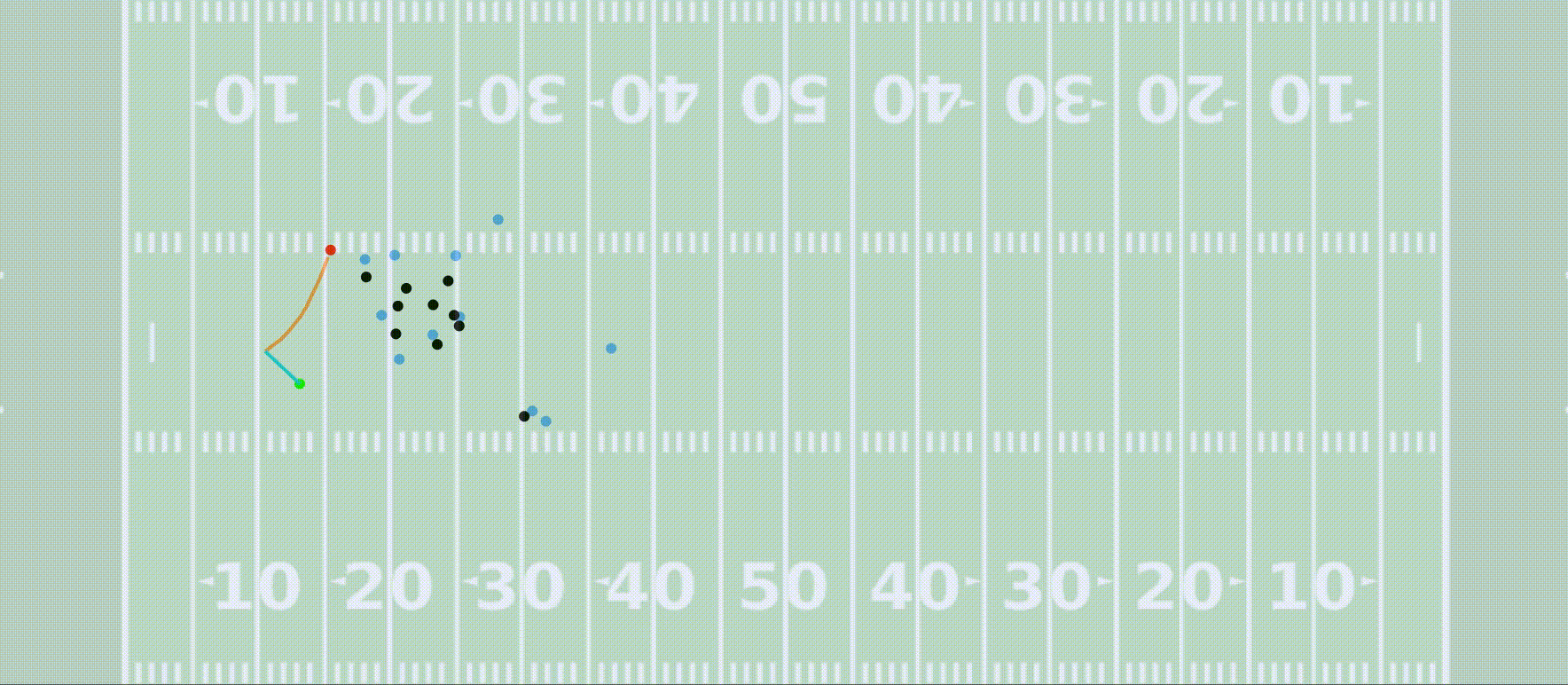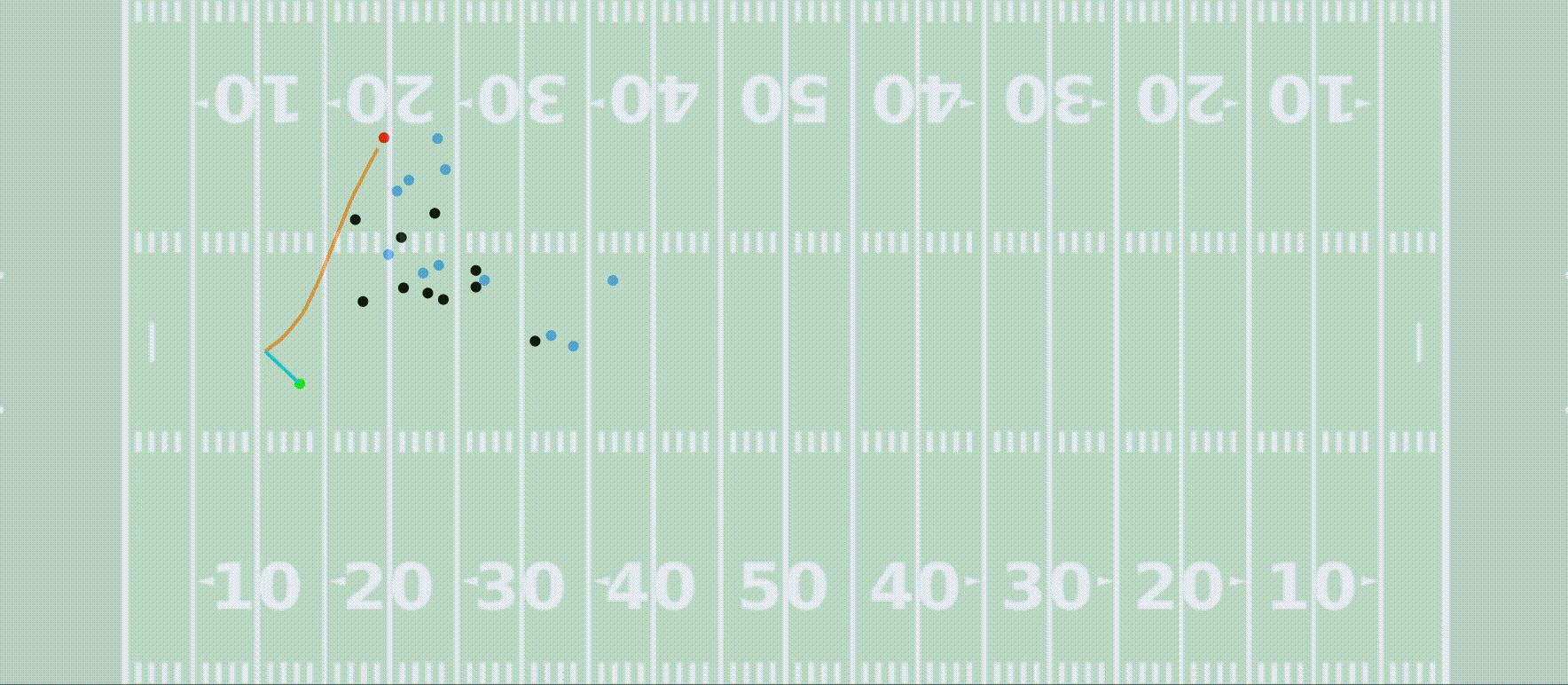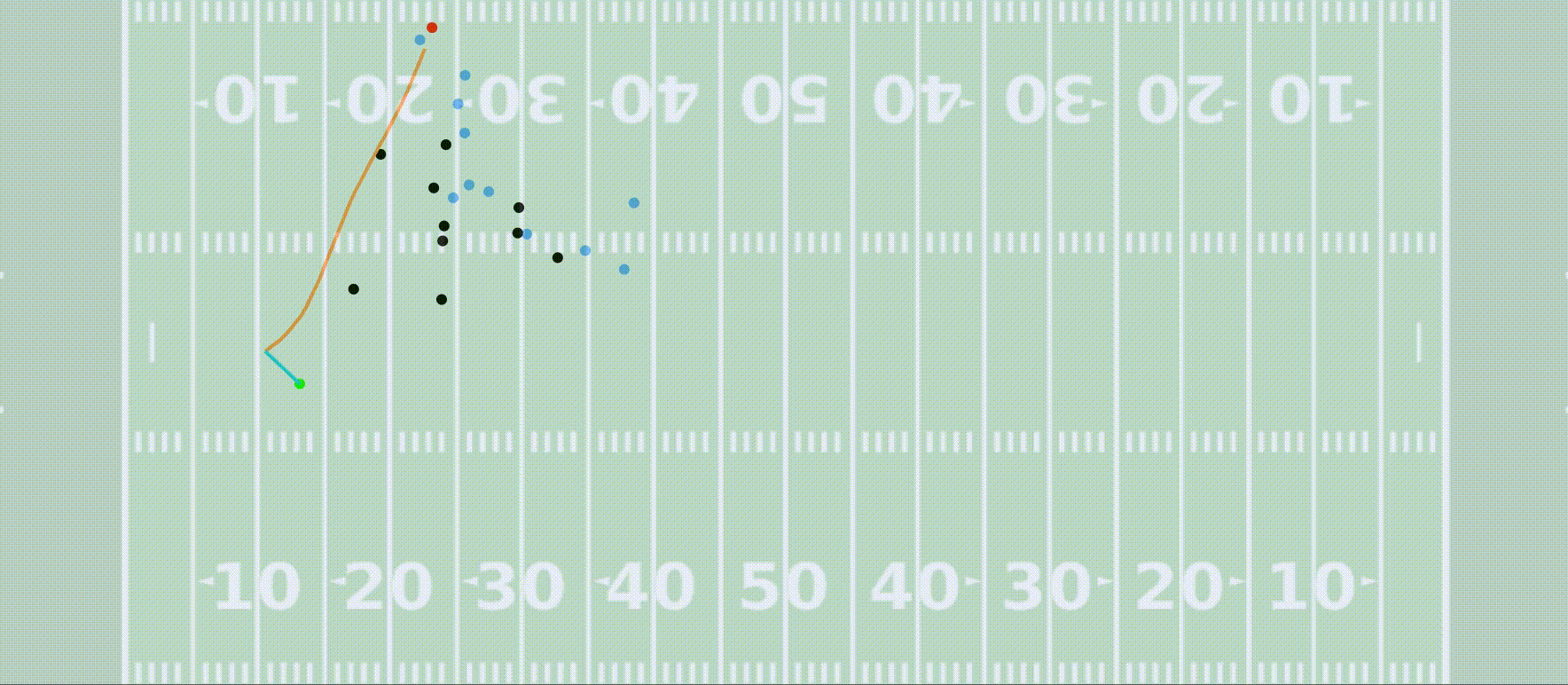
In my free time I like to dabble in sports analytics a bit. I (along with a few other Penn grad students) was named a finalist for the 2022 NFL Big Data Bowl! You can check out our Kaggle notebook as well as the NFL’s press release announcing the finalists and my team’s video presentation of our project.
Our submission showed how high resolution player-tracking data allows us to train a model that predicts the outcome of a kick return, and we develop a framework for using this to compute optimal return paths and evaluate player decision-making.